初めてのはてぶ投稿なのでテストがてら書いていく。元論文はこちら↓
論文:Hindsight Experience Replay
Abstract
・強化学習問題でスパースな報酬(エージェントが行動を起こしても得ることが困難な報酬)を扱うことは最も大きな課題の1つとして挙げられる。
・提案手法のHindsight Experience Replay(HER)はスパースかつバイナリ(ゴールしたら1それ以外0もらえるような報酬)である報酬からサンプル効率の良い学習を可能にし、複雑な報酬設計の必要性を回避してくれる。また、任意のオフポリシーなアルゴリズムに適用も可能。
・実験ビデオ:
Introduction
・ロボット工学(他でも重要だとは思うが)にとって共通の課題は、手元のタスクを反映するだけでなく、方策の最適化を導くために慎重に報酬設計をする必要がある。しかし、報酬設計は強化学習の専門知識とドメイン特有の知識が必要であり、環境によってどの程度の行動が許容されるか分からないなど設計が難しい。
・上記の理由より、報酬設計しないでいいようなバイナリ報酬から学習できるアルゴリズムを開発することは実用的に必要である。
・現在のモデルフリーにはできないが、人間は「失敗から学ぶ」ことができる。
・例として、アイスホッケーのパックをシュートしてゴール右側に外れたとする。人間はここから目標の位置に調整するなど学習できるが、モデルフリーは失敗からは学習することができない。ネットがさらに右側に置かれていれば、この一連の動作は成功していたという結論を導き出すことは可能で、HERではこの種の推論を実行することができる。
Methods
A motivating example
bit-flippingという環境でHERありとHERなしの実験をおこなった。状態空間はで、行動空間は
、
は整数で
番目の行動をすると
番目の状態bitを反転させる。各エピソードについて、初期状態と目標状態を一様にサンプリングし、目標状態にない限り、-1の報酬を得る。例:

・この環境に対してブーストラップ、カウントベース、VIMEを利用しても役にたたない。(膨大な状態を探索しきるのが非現実的)
・解決策として毎ステップ報酬が得られるような報酬設計をすることが挙げられるが、複雑なタスクになってくると設計は困難になる。
・報酬設計の代わりに状態シーケンスとゴール
のエピソード(つまり目標
にたどり着けなかったエピソード)について考える。このエピソードの経験で目標
への行き方は学べないが、状態
への行き方を学ぶことができそう。
・これをオフポリシーRLで利用するには・・・リプレイバッファ内の目標の部分を状態
へ置き換えれば実現できる。こうすることで、リプレイ内の軌跡の半分以上には-1以外の報酬が含まれており、学習が非常にシンプルに。
・図1でDQNとDQN+HERの性能を比較できる。
Multi-goal RL(まだ少し理解が追いついてない)
・複数の異なるゴールを達成するために学習するエージェントを訓練する。Universal Value Function Approximators(UVFA) のアプローチに従って、状態だけでなく、目標
も入力とするポリシーと価値関数を訓練する。
・すべての目標は
に対応していて、エージェントの目標は
を満たす任意の状態
を達成することであると仮定する。
・例:とし、与えられた
座標で任意の状態を実現したいとする。この場合、
とし、
とする。さらに、ある状態
が与えられたとき、その状態で満たされる目標
を簡単に見つけることができると仮定する。厳密に書くと写像
が与えられてると仮定する。各目標が達成したい状態に対応する場合、すなわち
で
の場合、写像
は恒等写像となる。2次元の状態と1次元の目標の場合、この写像は非常に単純な
となる。
・ユニバーサル・ポリシーは、任意のRLアルゴリズムを用いて、いくつかの分布から目標と初期状態をサンプリングし、エージェントをいくつかのタイムステップで実行し、目標が達成されなかったときに、タイムステップごとに負の報酬を与えることによって、訓練することができる(UVFAの論文を参照したほうが良い)。しかし、実際にはあまりうまくいかないので、HERを用いる。
Algorithm

・HERはこのように達成しやすい目標から難しい目標に移行していくため、暗黙的なカリキュラム学習と見ることができる。
Experience
実験環境・設定
・Multi-goal RLのための一般的な環境はないので、著者自身で環境を作成した。すべての実験で2本の平行したグリップを持った7-DOF Fetch Robotics armを使用する。このロボットはMuJoCoの物理エンジンでシミュレーションする。
・ポリシーは活性化関数ReLUを使用したMLPで構成され、訓練にはAdamをオプティマイザーとしたDDPGを使用。学習効率を上げるために毎更新後にパラメーターを平均した8体のウォーカーを使用。
・タスクは以下の3つ
- pushing:ロボットの前に置かれたテーブル上の箱を目標地点へ動かす。グリップはロックされている。
- sliding:パックを長いすべりやすいテーブル上の目標地点で停止するように叩く。
- pick-and-place:pushingの目標地点が空中にあって、グリップが解放されてるバージョンのタスク。※タスクの探索を容易にするために、ボックスをつかんだ単一の状態を記録し、この状態からトレーニングエピソードの半分を開始した。(このタスクを一からトレーニングすることはできなかったみたい)
・状態:すべてのロボットジョイントの角度と速度、およびすべてのオブジェクトの位置、回転、速度(線形と角度)で構成
・目標:、
の一定許容範囲で物体の望まれる位置を記述する。HERで使用される状態からゴールへのマッピングは
である。
・報酬:スパースな報酬を使用
・状態目標分布:すべてのタスクにおいて、グリップの初期位置は固定され、オブジェクトとターゲットの初期位置はランダム化
・観測:グリップの絶対位置、物体と目標位置との相対位置、および指間距離を入力として与える
・行動:行動は4次元で表現され、3次元は次タイムステップでの望まれる相対的なグリップ位置を指定、残りの1次元は位置制御される2本のグリップ間の望ましい距離を指定。
・リプレイのためのゴールサンプル方法:HERでは各エピソードの最終状態に対応する目標
でリプレイを行う。
実験結果
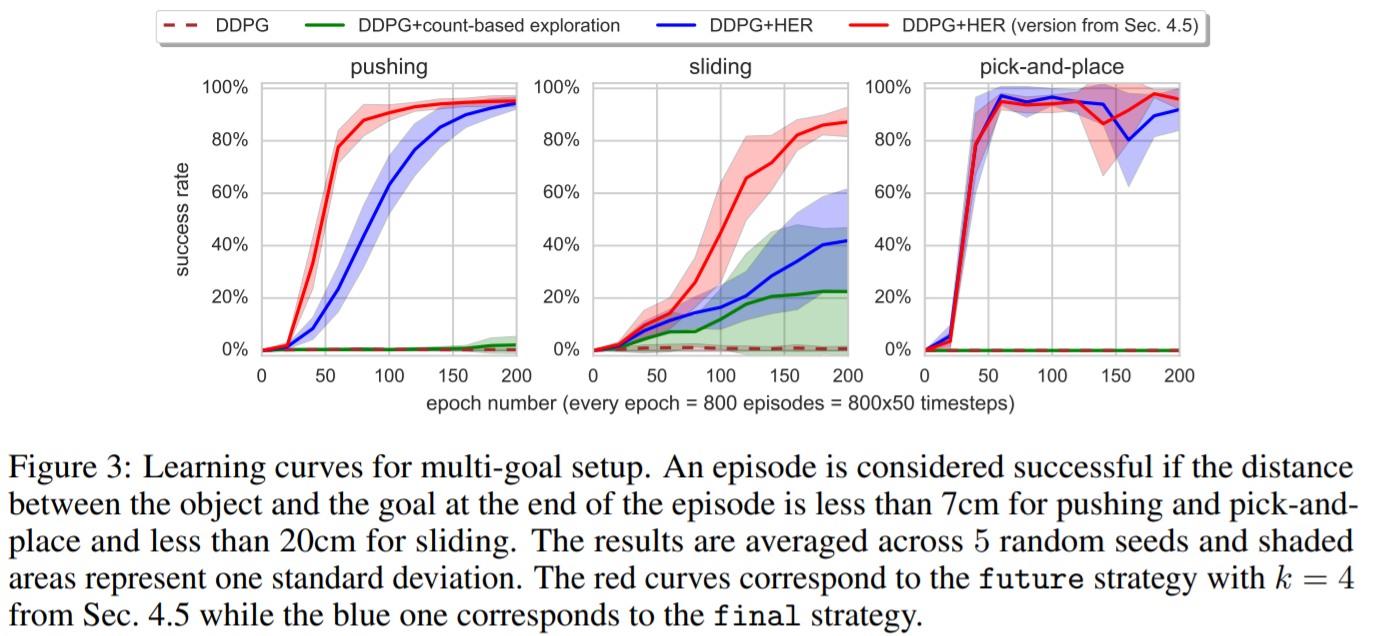
・マルチゴールの実験結果。DDPGのみとカウントベース手法は成功率がとても低いが、HERを取り入れたDDPGは学習ができているのが分かる。
・HERでは2回リプレイバッファに保存していて、1回がエピソードの生成に使用される目標で、もう1回がエピソードからの最終状態に対応する目標。
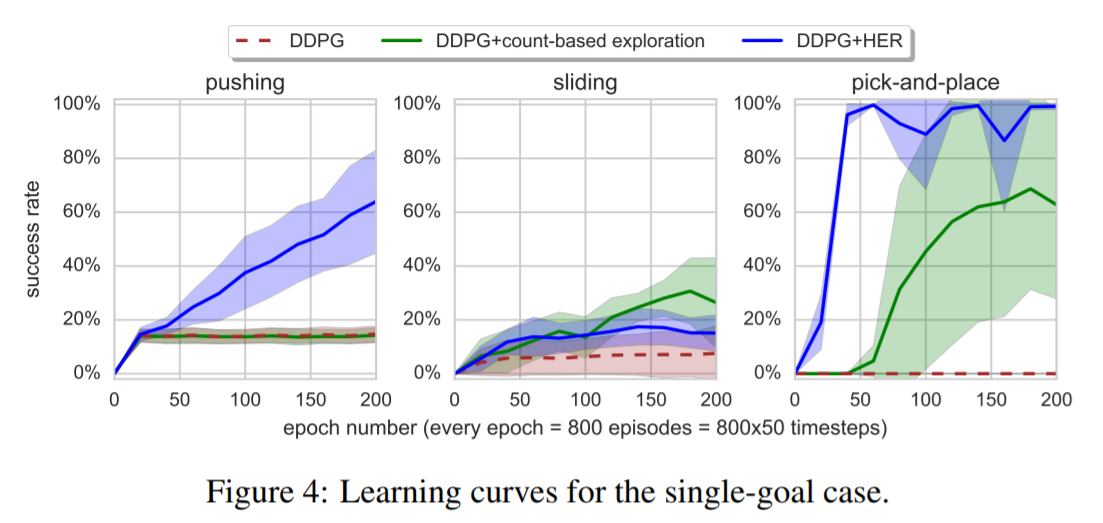
・シングルゴールの実験結果。なぜかSec.4.5バージョンのHERがここでは比較されていない。
・シングルゴールでも性能は上がるが、マルチゴールのほうが学習が早くなる。
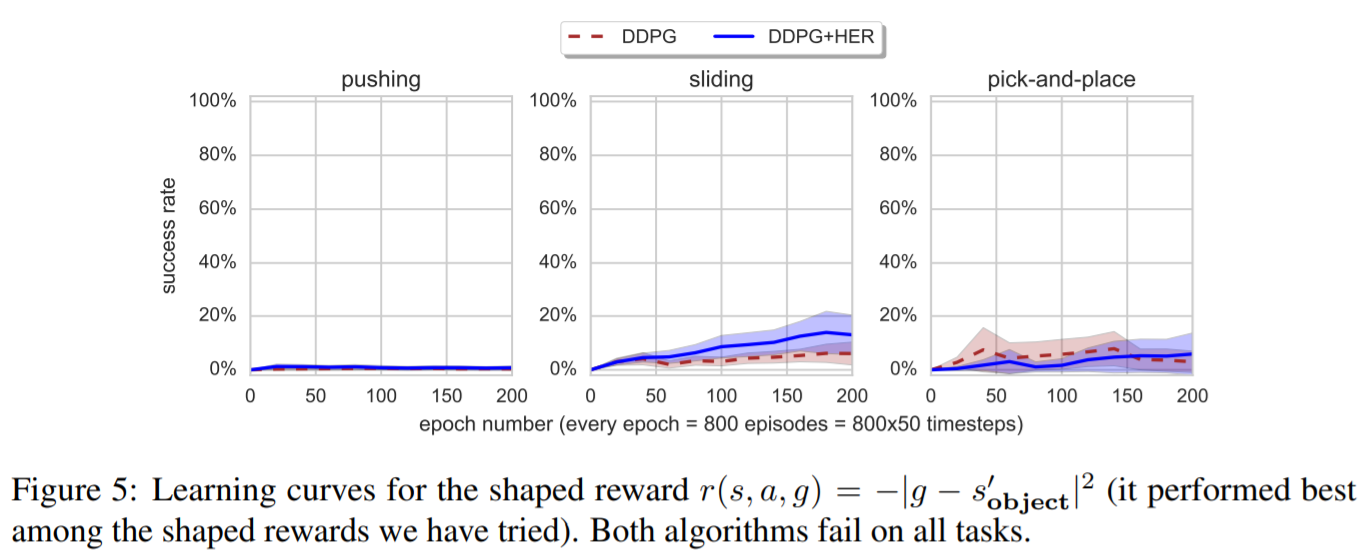
・報酬設計を行った場合、HERを利用すると学習がうまくできなくなる。
・原因として述べられているのが、(1)最適化するもの(すなわち、設計した報酬関数)と成功条件(エピソード終わりに目標位置から半径内に物体があるかどうか)の間に大きな不一致がある。(2)設計した報酬関数は、探索を妨げる可能性のある不適切な行動(例えば、箱を間違った方向に移動させる)に対してペナルティを与える。これは、エージェントが箱を正確に操作できない場合、全く箱に触れないことを学習させる可能性があり、実験のいくつかでこのような行動が起こったようです。
How many goals should we replay each trajectory with and how to choose them?
・HER で使用するゴールを選択するための異なる戦略(Alg.1 の )を実験的に評価する。
- final:リプレイに使用した追加目標は環境の最終状態に対応するもの
- future:リプレイされるトランジションと同じエピソードで、その遷移の後に観測された
個のランダムな状態でのリプレイ
- episode:リプレイされるトランジションと同じエピソードから来る
- random:学習全体でこれまでに遭遇した
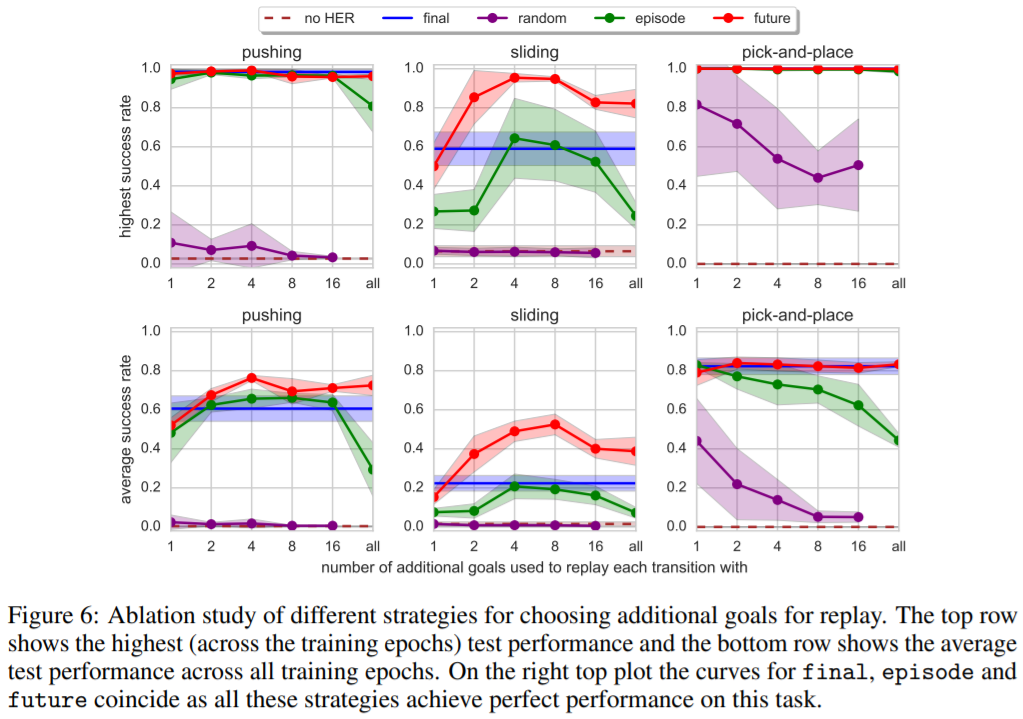
・異なる戦略と異なるkの値を比較したグラフで、このプロットからrandomを除くすべての戦略が、の値に関係なく、pushingとpick-and-placeをほぼ完璧に解いていることがわかる。
・リプレイにとって最も価値のある目標は、近い将来に達成されようとしているものでの値を 8 以上にすると、バッファ内の通常のリプレイデータの割合が非常に低くなるため、性能が低下する。
Conclusion
・Hindsight Experience Replayと呼ばれる手法はオフポリシーRLアルゴリズムをスパースとバイナリ報酬の問題に適用することを可能にした。